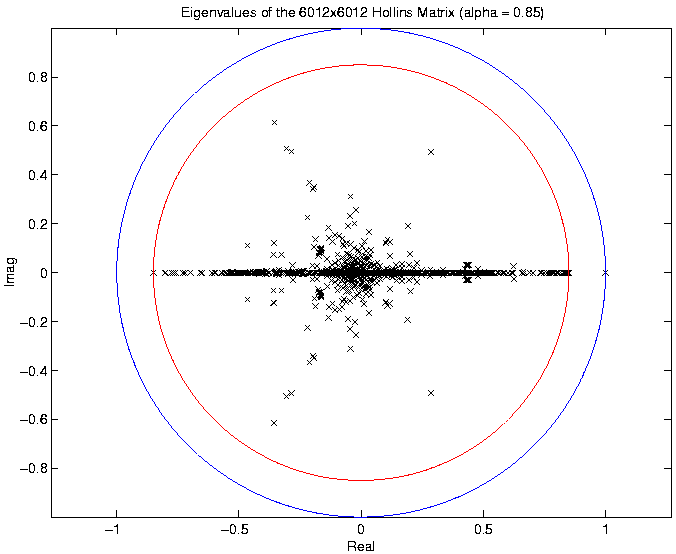
Pagerank and Web-based Information Retrieval
Crawler
Follow these steps to download, modify, compile, and install Webbot on a Unix/Linux machine.
It is a quick
and throrough crawler, but I found a small modification necessary to get complete link relationship text output.
- Download Webbot version 5.4.0 (it comes with the Libwww library)
- I have made two small changes to the source code:
- Text logging does not recognize destination links more than once, even if referred to by distinct pages.
SQL logging may count all links, but I couldn't get libwww to compile with mysql.
If you use Robot/src/HTRobot.c, all links are logged (prefixed by :::: so you can grep them out).
- Webbot will prompt you for the directory to store temporary files. This can get annoying,
so I removed the user input query by changing Library/src/HTDialog.c
- configure --with-regex, make, make install
Webbot supports many options, which define or restrict the depth and breadth of the crawl.
Here is an example bash script.
Data
- Langville and Kamvar have several good data sets (see links below).
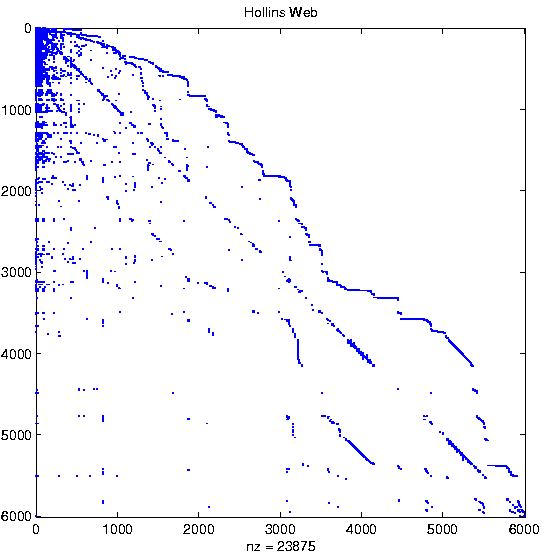
- hollins.edu webbot crawl (Jan '04)
Code
Pictures
Reports
Researchers
Links
Kenneth Massey, June 1, 2004
{kind=link}
{kind=link}
{kind=link}